RubySlippers
A multi-modal interface that supports efficient content-based voice navigation of video tutorials through keyword-based queries.
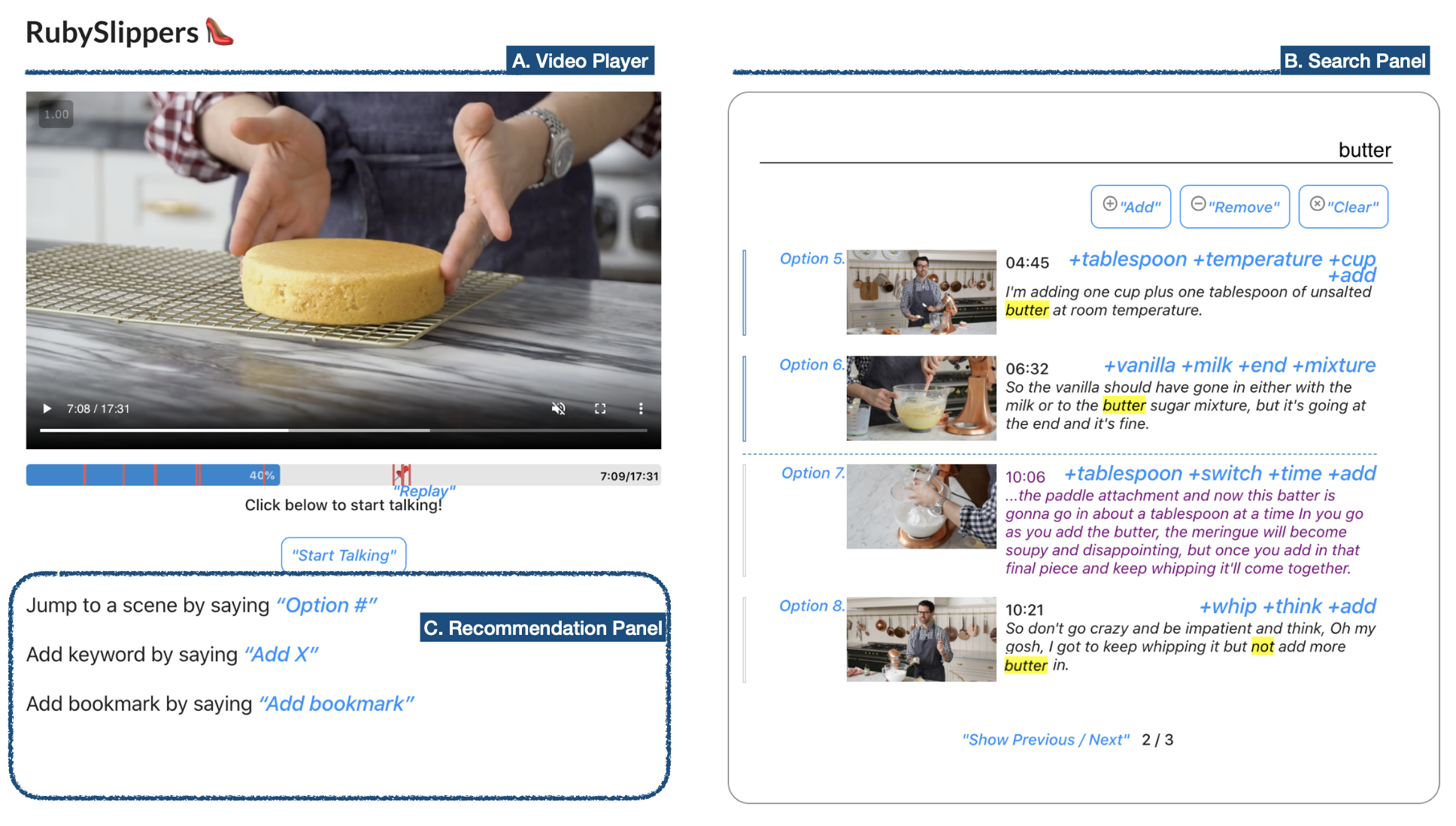
Directly manipulating the timeline, such as scrubbing for thumbnails, is the standard way of controlling how-to videos. However, when how-to videos involve physical activities, people inconveniently alternate between controlling the video and performing the tasks. Adopting a voice user interface allows people to control the video with voice while performing the tasks with hands. However, naively translating timeline manipulation into voice user interfaces (VUI) results in temporal referencing (e.g. “rewind 20 seconds”), which requires a different mental model for navigation and thereby limiting users’ ability to peek into the content. We present RubySlippers, a system that supports efficient content-based voice navigation through keyword-based queries. Our computational pipeline automatically detects referenceable elements in the video, and finds the video segmentation that minimizes the number of needed navigational commands. Our evaluation (N=12) shows that participants could perform three representative navigation tasks with fewer commands and less frustration using RubySlippers than the conventional voice-enabled video interface.