
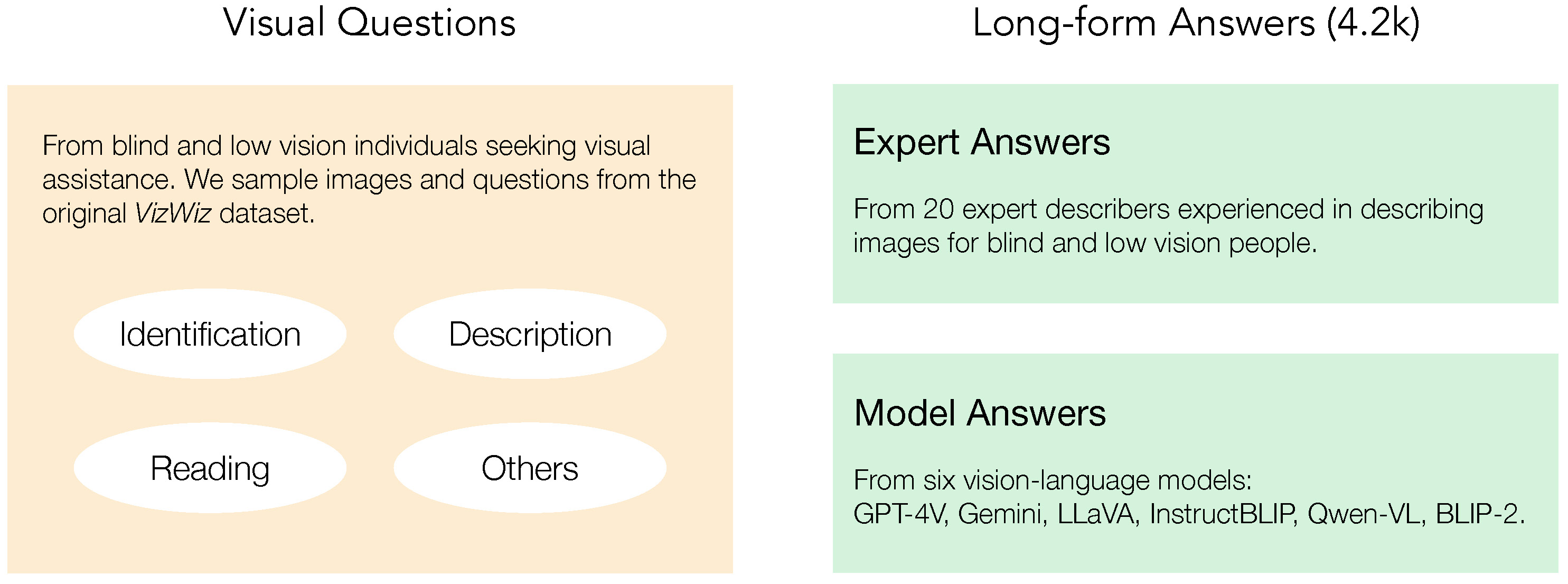
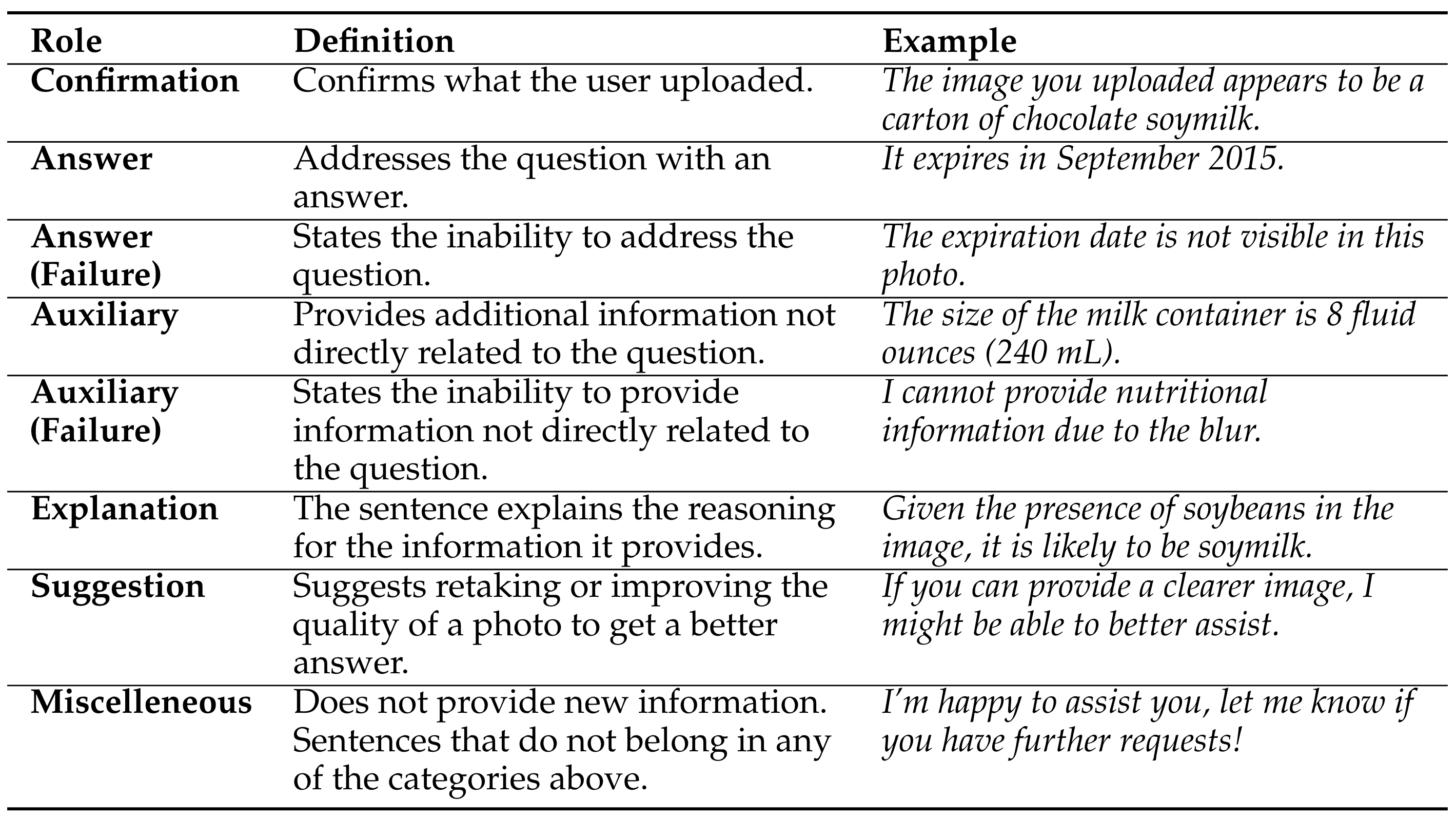
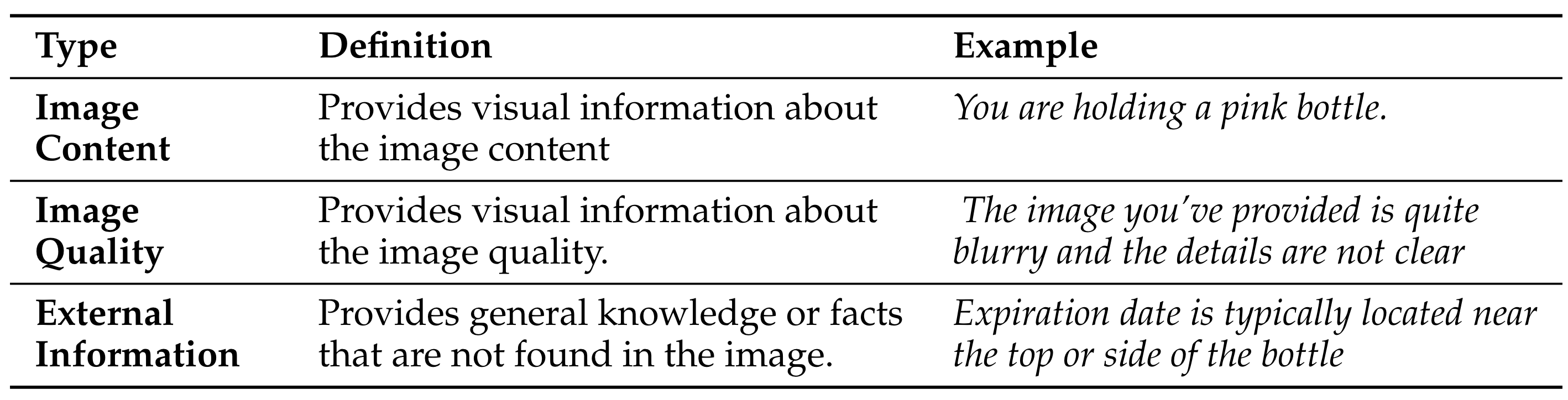
Vision language models can now generate long-form answers to questions about images – long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences in LFVQA and demonstrate that long-form answers contain information beyond the answer such as explanations and suggestions. We further evaluate 360 long-form answers with BLV and sighted people to understand their preferences and assess the correctness of the long-form answers. Long-form answers generated by models often hallucinate with incorrect information to unanswerable questions (e.g., blurry images), yet BLV people often perceive these long-form answers as correct. To reduce hallucinations, we evaluate VQA models on their ability to correctly abstain from answering unanswerable questions.

@article{huh2024long,
title={Long-Form Answers to Visual Questions from Blind and Low Vision People},
author={Huh, Mina and Xu, Fangyuan and Peng, Yi-Hao and Chen, Chongyan and Murugu, Hansika and Gurari, Danna and Choi, Eunsol and Pavel, Amy},
journal={arXiv preprint arXiv:2408.06303},
year={2024}
}